

Bonsoir,
Alors ce soir j'ai décidé de vous parler des indexes (les B-TREE). Comme vous le savez peut-être leur nom vient du fait que si l'on schématise l'index on obtient un arbre avec des feuilles d'ou la terminologie.
Globalement, lorsque l'on parle de maintenance d'indexes et donc de reconstruction d'indexes, on obtient de nombreuses variantes. Juste pour rire, voici les plus fréquentes:
- "Ca ne sert à rien de reconstruire les indexes, car aucun impact sur les performances"
- "Il faut reconstruire les indexes toutes les semaines..."
- Et puis on ceux qui se demandent pourquoi reconstruire les indexes, puisqu'il est connu de facon notoire qu'ORACLE fait tout et tout seul. Faut bien justifier qu'un DBA ne sert à rien.
Si vous avez déjà lu certains articles sur ce blogs, vous devez commencer à savoir que je suis partisan des démonstrations et que surtout vous ne devez pas vous faire dicter votre façon d'administrer vos bases par des "idées reçues". SI vous faites quelque chose il est bon de savoir pourquoi vous le faites.
Pour cela, je vais prendre une table T_4 avec deux colonnes de type number (i et j).
Et je vais créer une clé primaire sur i, après avoir renseigné la table avec quelques 2 millions de lignes.
Ensuite, je vais supprimer aléatoirement un certain nombre de valeur pour simuler une activité sur la table.
CREATE TABLE T_4 (i NUMBER, j NUMBER);
ALTER TABLE T_4 ADD CONSTRAINT PK_T4 PRIMARY KEY(i);
/*Remplissage */
BEGIN
FOR z IN 1..2000000 LOOP
INSERT INTO T_4 VALUES (z,TRUNC(DBMS_RANDOM.VALUE(1,345000)));
END LOOP;
COMMIT;
END;
/
/*suppression aléatoire de lignes */
DECLARE ligne_a_supprimer NUMBER;
BEGIN
FOR z IN 1..1000000 LOOP
ligne_a_supprimer := TRUNC(DBMS_RANDOM.VALUE(1,2000000));
DELETE FROM T_4 WHERE i=ligne_a_supprimer;
END LOOP;
COMMIT;
END;
/
EXEC DBMS_STATS.Gather_Table_Stats(user,'T_4',CASCADE=>TRUE);
A la fin des ces manipulations, il me reste un peu plus d'1.2 millions de lignes dans ma table.
Il ne faut pas oublier qu'un index a pour objectif d'accélere l'accès au données. Seulement lors de la suppression de lignes l'index n'est pas reconstruit et par conséquent l'indexes conserve des feuillezs avec des plages de valeurs n'existant plus. C'est ce genre d'opération qui va entrainer une fragmentation de notre indexes et par conséquent en réduire la performance.
Ex: Je veux compter le nimbre de lignes ayant une valeur pour i comprise entre 230000 et 612000.
SELECT COUNT(*) FROM T_4 WHERE i BETWEEN 230000 AND 612000;
La requete n'est pas complexe. Oracle va effectuer un IRS (Index Range Scan) sur la clé primaire.
Le plus simple est encore d'ouvrir une session SQL + en prenant soin d'activer AUTOTRACE, et puis également le chronomètre.
SET AUTOTRACE ON
SET TIMING ON
SELECT COUNT(*) FROM T_4 WHERE i BETWEEN 230000 AND 612000;
Résultat:

Les informations que nous avons ici, ne nous indiquent pas si l'indexe est fragmenté. Il revient au DBA de surveiller ses bases et d'automatiser certains traitements pour surveiller quels sont les indexes à reconstruire. En effet, on ne peut pas se satisfaire de reconstruire tous les indexes de façon périodique. Je concède que sur des bases à faible volumétrie, cela n'est pas un souci, mais sur des tables de plusieurs dizaines ou centaines de millions de lignes,cela pourrait vite devenir problématique.
Dans le cas présent, je vais faire les manipulations de façon manuelle, et (peut-être) dans un post prochaine, je publierai un script pour automatiser la chose.
Avant tout pour savoir, si un index mérite d'être reconstruit,il faut avoir des informations dessus et pour cela nous allons devoir analyzer l'indexe pour récupérer des informations que malheureusement nous n'avons pas dans la vue USER_INDEXES.
ANALYZE INDEX PK_T4 VALIDATE STRUCTURE;
La subtilité arrive ici. Oracle stocke les informations relatives à cette analyze dans la vue INDEX_STATS. Et le souci, c'est que cette vue ne contient que les informations relative à la dernière instruction "ANALYZE .... VALIDATE STRUCTURE;" et donc cette vue renverra toujours qu'une seule ligne !
Cette vue dispose d'un certain nombre de colonne, et pour ceux que cela intéresse, je vous invite à vous rendre sur la documentation en ligne Oracle:
http://download.oracle.com/docs/cd/B19306_01/server.102/b14237/statviews_4216.htm#sthref2014
En ce qui me concerne uniquement certaines colonnes vont m'interesser.
Effectuons la requête suivante:
Si j'ai choisis ces colonnes ce n'est evidement pas par hasard.
En effet, il existe certaines règles indiquant que :
-1/ Que si la valeur de "height" qui représente la profondeur de l'arbre de l'index est supérieur à 4, alors il faut reconstruire l'indexe.
-2/ Que si le ratio entre le nombre de lignes supprimées dans les pages d'indexe par le nombre total de lignes dans les pages d'indexe est supérieur de 20 à 30%, alors il faut reconstuire. Il n'y pas de valeur fixe, et cela dépendra certainement de votre volumétrie, de votre matériel, et des requêtes impliquées dans l'utilisation de ces indexes.
La règle d'or reste : Tester, mesurer avant et après et apprenez à dompter votre base.
Dans mon cas j'obtiens à un ratio de l'ordre de 36%, je décide donc de reconstruie l'index.
ALTER INDEX PK_T4 REBUILD;
Dans la foulée j'enchaine une nouvelle analyze
ANALYZE INDEX PK_T4 VALIDATE STRUCTURE;
Et sans surprise, j'obtiens un ratio de 0 puisque je viens de reconsruire l'index.
Reste à vérifier l'impact sur les performances. Afin de ne pas fausser un eventuel mise en cache des données, je me connecte en system pour vider le buffer cache.
CONNECT SYSTEM/*****
ALTER SYSTEM FLUSH BUFFER_CACHE;
Puis je me reconnecte en owner:
SET AUTOTRACE ON
SET TIMING ON
SELECT COUNT(*) FROM T_4 WHERE i BETWEEN 230000 AND 612000;
Résultat:
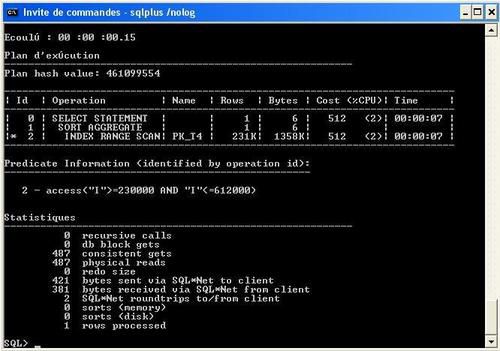
Que constate t-on ?
- Un gain de temps (0.15 s contre 0.26 s)
- Et de facon plus significative 487 accès disques contre 801 avec notre indexe fragmenté. Car maintenant nous pouvons parlé d'indexe fragmenté.
Dans notre exemple nous avons utilisé une petite table avec uniquement deux colonnes et une clé primaire. Mais il n'est pas rare dans une base d'avoir des centaines de tables qui subissent des insertions, et des suppressions de façon fréquente. Si l'on ajoute cela à des requêtes surement bien plus compliquées que celle que je viens de faire, on peut obtenir une application qui rame....
Gardez cela à l'esprit. Il arrive parfois (en tant qu'editeur) que l'on demande un dump à notre client qui a des problèmes de performances que l'on n'arrive pas à reproduire. Le soucis, c'est que lorsque vous allez importer, vous allez forcement reconstruire les indexes et donc faire disparaitre une éventuelle source du problème !
LAO.


